olá Pessoal,
O post de hoje é como popular um banco de dados tendo os dados em um arquivo XML. Se ainda não passou por esse requisito no seu trabalho, não se preocupe que o momento vai chegar. Há várias formas de fazer a leitura do arquivo XML e popular o banco, para o post, escolhi o Xstream e o Hibernate, que já uso o Hibernate por default e o Xstream é de fato uma boa API. Há também a SAPX, que não cheguei a testar.
Lets go…
Requisitos
- Java 5/superior
- Hibernate 3.x/Superior
- Eclipse IDE
- Xstream : faça o download da API
- MySql 5
Iniciando
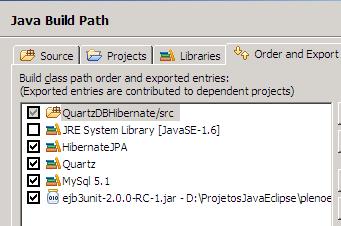
Para inicio você precisa criar um Java Project no seu Eclipse, e ter as bibliotecas do Hibernate adicionadas ao projeto. Não esqueça de adicionar os .JARS do MySql e do XStream (apenas xstream-1.3.1.jar). Abaixo temos o nosso banco vazio, aguardando os dados do XML.

Vamos usar annotations para o mapeamento do nosso bean com o Hibernate, se tiver dúvidas de como fazer isso, terá que ver alguns posts meus mais antigos de Hibernate com annotations.
A seguir temos a imagem de como vai ficar nosso projeto. Você já pode ir adicionando as classes e as bibliotecas, ao decorrer do post, vamos apresentando os códigos relevantes.

Antes de mais nada faça o download do nosso arquivo XML que possui os dados dos usuarios que vamos popular, e adicione ele à raiz do projeto. Para fazer isso basta clicar com o botão direito no projeto, escolher importar ==> File System e buscar pelo arquivo XML no seu computador.
Baixar o usuarios.xml
note: no arquivo usuarios.xml não temos o campo id para representar a coluna no banco, uma vez que este será gerado de forma automatica. Então ao abrir o arquivo sentirá falta dele.

Resolvi colocar poucos dados no XML, mas se funcionar com 2-3, deve está ok com 10,20 etc. (teoricamente sim).

Na imagem acima temos o projeto atualizado com o arquivo xml.
Pronto. Acho que até aqui estamos ok. Na próxima etapa serão os codes das classes que vamos precisar para trabalhar de verdade.
Desenvolvimento
Primeiramente você deve criar o Bean, ou seja, a classe Usuario e fazer as devidas anotações, conforme o code abaixo. Removi os getters/setters, para poupar espaço:
@Entity
@Table
public class Usuario {
@Id
@GeneratedValue
private int id;
@Column
private String nome;
@Column
private String email;
@Column
private String senha;
@Column
private String tipo;
Agora, configure o seu arquivo hibernate-cfg.xml com os dados de conexão do seu banco. Não esqueça de definir o mapping para a classe bean, veja como ficou o meu:

Agora vamos criar os metodos para persistência em nossa classe HibernateDAO, ficando assim:
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.AnnotationConfiguration;
public class HibernateDAO {
private static final ThreadLocal<Session> threadLocal = new ThreadLocal<Session>();
private static final SessionFactory sessionFactory = new AnnotationConfiguration().configure().buildSessionFactory();
public Session getSession() {
Session session = threadLocal.get();
if (session == null) {
session = sessionFactory.openSession();
}
return session;
}
public void begin() {
getSession().beginTransaction();
}
public void commit() {
getSession().getTransaction().commit();
}
public void rollBack() {
getSession().getTransaction().rollback();
}
public void close() {
getSession().close();
}}
Agora vamos atualizar a classe UsuarioDAO que é a classe que solicita que a persistência aconteça.
public class UsuarioDAO extends HibernateDAO{
public void create(List<Usuario> listUser){
for (Usuario usuario : listUser) {
begin();
getSession().save(usuario);
try{
commit();
}catch (HibernateException e) {
e.printStackTrace();
rollBack();
}
}}}
Para quem já trabalha com Hibernate nada de especial até aqui. Lembrando que o objetivo do post não é explicar Hibernate e sim, mostrar como popular dados de um XML no banco.Então não vou entrar em detalhe sobre o code acima, qualquer dúvida basta consultar outros posts meus que explico em detalhe o Hibernate.
Vamos atualizar a classe LerDadosXML, que como nome já diz, ela será responsável
public class LerDadosXML {
private List<Usuario> listUsuario;
public List<Usuario> lerXml(Reader fonte){
XStream stream = new XStream(new DomDriver());
stream.alias(“Usuario”, Usuario.class);
List<Usuario> fromXML = (List<Usuario>) stream.fromXML(fonte);
popularData(fromXML);
return fromXML;
}
public void popularData(List<Usuario> listUsuario){
new UsuarioDAO().create(listUsuario);
}
}
Bom, a única novidade que temos ai é o uso da API XStream que será responsável por ler os dados do XML. Para ler os dados, como pode ver é bem simples, basta chamar xStream.fromXML(fonteOrigem); no nosso caso o local onde está o arquivo XML deverá ser passado para o argumento do método, mas poderiamos definir isso na mão grande algo como readerFile = new FileReader(new File(“nomedoarquivo.xml”));
Testando
Para testar e ver se de fato que planejamos vai acontecer, farei um unit test. Se não quiser usar unit test, pode criar a classe com o método main e executar.
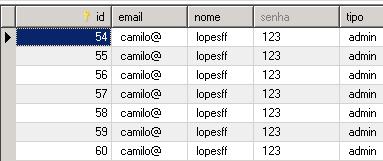
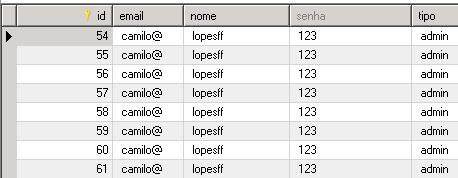
A seguir temos o test passando e o banco populado:
public class LerDadosXMLTest {
@Test
public void testLerDadosXMLEPopulaNoBanco() throws FileNotFoundException{
FileReader fileReader = new FileReader(new File(“usuarios.xml”));
LerDadosXML lerDadosXML = new LerDadosXML();
assertFalse(lerDadosXML.lerXml(fileReader).isEmpty());}
}


Bom vou ficando por aqui, espero que tenham gostado do post.
Abracos, see ya!!