
olá pessoal,
O post de hoje é algo bem iniciante, mas ainda muito usado quando estamos trabalhando com protipo de algo e precisamos apenas validar se uma solução vai funcionar de fato. Ou seja, quando estamos na ponta do iceberg. Então hoje, vou mostrar como criar um arquivo JAR pelo Eclipse, mas não será um arquivo JAR qualquer com um “Hello World” apenas, este terá que connectar à um banco de dados MySQL e ainda o Quartz. Então somente neste contexto temo três APIs externas no aplicativo, pois o Hibernate fará o terceiro.
Lets go…
Alguns requisitos:
- ter o hibernate configurado, dúvidas consulte outros posts do Hibernate aqui.
- ter todas as libs no projeto
- antes de criar o JAR, certifique-se que tudo funciona no modo de DEV(hibernate, conexão com banco etc. Rode e check os resultados inúmeras vezes;
- tenha o MySQL 5/superior instalado;
Starting…
Vamos dizer que você precise mostrar a funcionalidade de algo da maneira mais simples possível, e quem for ver está mais preocupado na funcionalidade do que em layout, performance (por enquanto). Como trabalho com pesquisa e desenvolvimento tenho passado por isso com bastante frequência, uma vez que no inicio de algo estamos no prototipo para uma possível nova feature, solução, seja o que for, mas não é legal no inicio gastar muita energia, com performance, layout, ou qualquer caracteristica que não agrega valor na funcionalidade. Caso a ideia não seja válida, o resultado será que gastei menos energia e tempo. E já foi possível descartar.
Situação
Um dia desses tive que apresentar uma solução para uma feature do projeto que, nem sabiamos se ia dar certo e como seria os impactos. Daí começamos com as investigações e pesquisa necessária, e quando fomos apresentar para os arquitetos, o team de Q.A etc. Foi algo bem produtivo porque geramos um JAR com o banco HSQLDB, distribuimos esse JAR e eles só executaram e viram o resultado desejado (não posso dar maiores detalhes). Já pensou se fosse necessário ter que montar todo o ambiente de DEV na maquina de quem fosse validar a solução? Exemplo: de ter que instalar um banco real, configurar os acessos etc. Bem, nada produtivo né?
HSQLDB: é um banco em Java que não passa de JAR e que por sinal é bem completinho, porém com suas limitações e não queira comparar ele com MySQL, SQL Server, Oracle etc . Basta adicionar o .jar ao seu projeto e terá o HSQLDB disponível para receber os dados. Claro que terá que informar ao hibernate.cfg.xml sobre isso. Qualquer dúvida, basta dar uma “googlada” que encontrará vários posts a respeito de como usar o HSQLDB. A documentação também ajuda: http://hsqldb.org/ http://pt.wikipedia.org/wiki/HSQLDB
Note
Aqui vamos usar o MySQL 5 então vou levar em conta que você já tem ele instalado na sua maquina. Também, acredito que já tem o projeto do ultimo post rodando. Mas, caso não tenha use qualquer outro projeto pessoal que tenha acesso à um banco de dados, que use o hibernate, para ficar bem próximo do nosso.
Development
Eu poderia ter ido direto ao ponto e ter feito o post com 3,4,5 linhas, mas sempre gosto de fazer um contexto, para quem está lendo possa ter uma ideia da utilização, principalmente se está vendo o assunto pela primeira vez, é mais importante ainda, pois saber o porque das coisas é tão importante quando saber fazer. Não saia fazendo, por fazer. Sempre se pergunte o por que fazer isso?
- uma vez com o projeto criado no eclipse, clique com o botão direito e escolha build path → configure build path.
- agora precisamos informar as libs que serão exportadas
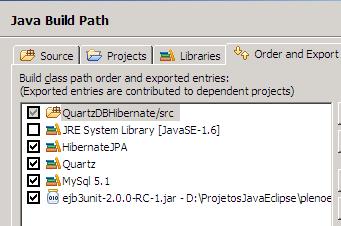
observe que marquei as bibliotecas que preciso. No caso do nosso exemplo são: hibernate, quartz e mysql.
- Clique em ok
- agora clique com o botão direito no projeto e escolha export
- procure pela pasta Java
- e escolha Runnable JAR e clique em next
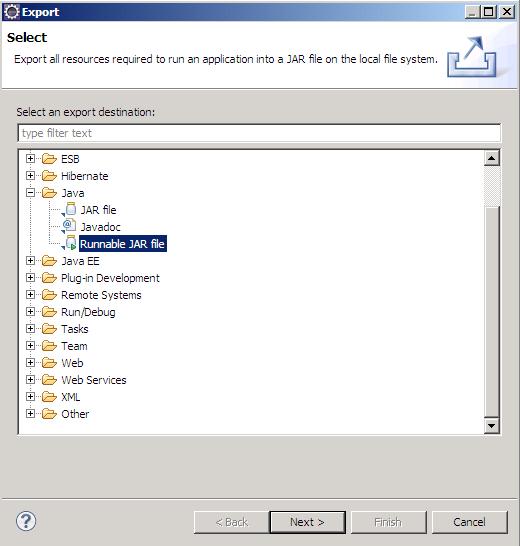
- agora precisamos informar o projeto, que no caso será QuartzDBHibernate

- indique o local que deseja salvar seu arquivo JAR.
- Clique em finish e aguarde terminar (talvez apareça um warning, se quiser clique em details leia e prossiga. Não é nada critico)
Uma vez com JAR gerado, vamos testar a execução. No caso do windows abra o promt de comando e navegue até onde salvou o seu JAR. E digite: java -jar quartzdbHibernate.jar (eu usei o mesmo nome do projeto, você deve informar o nome que deu ao arquivo JAR caso tenha sido diferente).
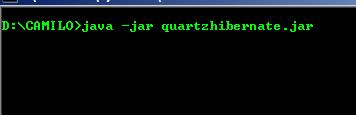
Agora vamos ver o resultado, ahh não esqueça de dar um START no seu MySql do contrário verá exceções na tela.

Observe que foi adicionado o usuario, o sql é printed pelo hibernate uma vez que configurei no hibernate.cfg.xml para ser impresso. Agora vamos ao banco.
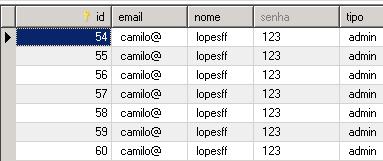
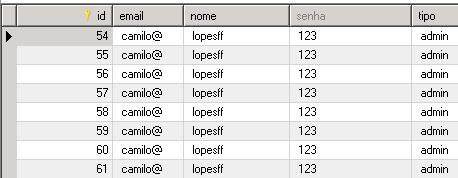
Na imagem acima temos o banco atual e veja que o ultimo ID é 60. na imagem a seguir temos o banco atualizado e o ultimo ID é 61:
Alguns profissionais “Senior” crucificaria o Camilo por fazer um post deste tipo, tão ABC. Mas, como sempre falei : “todo sênior hoje um dia deu hello world, e passou pelas mesmas dificuldades que alguem que está chegando hoje no mundo java está passando, e com certeza esse senior precisou de ajuda, e pq ignorar de dar essa ajuda hj ?”. O que tenho aprendido nesses 3 anos como blogueiro foi o seguinte: o mais prazeroso não é escrever um post “avançadao ou basicao” para querer mostrar que “sabe” algo. E sim saber, o que foi escrito teve um impacto positivo na vida do leitor independente do nível do post. Até hoje lembro das noites em claro que passei, para instalar e configurar o Java corretamente no windows, e a dificuldade que tive em fazer isso de forma automatica, sem precisar “googlar” fazer aquele javac funcionar era osso. E quando conseguir, virou meu primeiro post do blog, e foi onde tudo começou. E até tenhoo leitores comentando que o post tem salvado o dia deles.
Vou ficando por aqui e espero que tenham gostado do post.
abracos see you next post!!!






