olá Pessoal,
Quem aqui nunca teve vontade de adicionar o LOG4J ao seu projeto Java e teve dificuldades na primeira vez ?( levanta a mão o/) Apesar de ser um frameworks bem simples, para controle de log, é comum, para quem estava acostumado usar o System.out.println() ficar um pouco perdido, o objetivo deste post é apresentar como configurar o LOG4J e explicar dentro do code, como as coisas acontecem.
Lets go..
Introdução
O uso de uma API de LOG, é extremamente importante tanto durante o desenvolvimento, quanto já temos aplicação em produção. Pois, mais cedo ou mais tarde vamos precisar analisar o LOG por algum motivo. Situações comum que precisamos de um LOG:
- sua aplicação conecta à banco de dados e este está down, com certeza verá communication link failure como exceção e uma connection refused. Para que tudo isso não apareça na tela do usuário, mandamos para um arquivo de log e lá vamos investigar quando e que dia aquilo aconteceu;
- Sua aplicação vai ler um arquivo que é criado a partir de outra aplicação, se não encontrar o tal do arquivo teremos uma exceção e mandaremos ela para o arquivo de log. E daí vamos saber o dia, o horário que a outra aplicação parou de gerar aquele tal arquivo e daí iniciar uma investigação;
Claro que há vários contextos do uso de LOG, os citados acima, foi apenas uma das situações mais tradicionais.
Entendendo o Log4J
Para entender o framework, é preciso saber apenas três aspectos: Logger, Appender,Layout.
Logger: é o cara que recebe as solicitações de log. Podemos criar um logger para cada classe da aplicação, porém o framework já fornece uma padrão caso não seja informado nenhum.Appender: os Loggers eles precisam saber para quem enviar as informações que recebeu, e ai os Appenders faz o trabalho dele, dizendo : “Logger, passe as informações que você recebeu para mim, que eu saberei o que fazer com elas”.
Com o appender podemos decidir, salvar as informações de Logger em um arquivo, imprimir no console, enviar via e-mail etc.
Layout: precisamos definir o formato que estas informações serão armazenadas para isso precisamos de layout. Podemos, organizar em um formato HTML, Simple text etc. Com o layout podemos definir data e hora, linha onde o log foi gerado etc.
Níveis de Logger
Todo logger possui um dos 5 niveis disponíveis, DEBUG,INFO,WARN,ERROR e FATAL. Por default DEBUG é configurado por padrão pelo framework, caso você não defina nenhum.
Os níveis vão ajudar para saber que tipo de informação deseja gravar no seu LOG, por exemplo: você define que apenas os erros igual ou maior que WARN serão salvo no seu arquivo LOG. Isso é importante, pois às vezes não importa ter DEBUG,INFO em seu arquivo de LOG quando está em produção. Para o team de QA apenas interessa a partir de INFO, por exemplo. Mas, você pode criar dois arquivos de LOG, um para DEV e lá você põe todas as info desde DEBUG e para o log que vai junto com aplicação a partir de INFO. O framework permite esta flexibilidade de mandarmos diferentes níveis para arquivos diferentes.
A ordem: DEBUG < INFO < WARN < ERROR < FATAL.
Leitura simples: se você configura para WARN, somente será enviado mensagem igual ou acima de WARN. Quem é maior que WARN? (ERROR)
Step 1
Fazer download do JAR log4j.jar
http://logging.apache.org/log4j/1.2/download.html
Step 2
Adicionar ao projeto Java (ou crie um projeto Java)
O nosso projeto Java, vai salvar um dado no banco via Hibernate. Pois, iremos simular um erro e ver se este dado consta no arquivo de log.
Step 3 – configuração
A configuração de um arquivo do LOG4J pode ser feita de forma programaticamente ou através de um arquivo de properties. Vamos mostrar aqui ambos, primeiro veremos a configuração do arquivo de properties, onde os comentários já possuem as devidas explicações:
#### Usando 2 appenders, 1 para logar no console, outro para um arquivo
log4j.rootCategory=WARN,stdout,fileOut
# Imprime somente mensagens com ‘priority’ WARN ou mais alto para o logger
#lembrando a ordem: DEBUG – INFO – WARN – ERROR – FATAL
log4j.category.lopes=INFO
#### O primeiro appender escreve no console
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
### Pattern que mostra o nome do arquivo e numero da linha, porem sem data e hora
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) – %m%n
#### O segundo appender escreve em um arquivo e faz um bkp ao atingir o max
log4j.appender.fileOut =org.apache.log4j.RollingFileAppender
log4j.appender.fileOut.File=camilolog.log
### Controla o tamanho maximo do arquivo
log4j.appender.fileOut.MaxFileSize=100KB
### Faz backup dos arquivos de log (apenas 1)
log4j.appender.fileOut.MaxBackupIndex=1
log4j.appender.fileOut.layout=org.apache.log4j.PatternLayout
#####este formato esta em ingles: 2011-04-24 e imprime o nro da linha L
log4j.appender.fileOut.layout.ConversionPattern=%d [%t] %5p %c:%L – %m%n
####imprime no formato dia/mes/ano
#log4j.appender.fileOut.layout.ConversionPattern=%-2d{dd/MM/yy HH:mm} [%t] %5p %c:%L – %m%n
O interessante nesta configuração é a linha :log4j.category.lopes=INFO
Onde criei meu LOGGER e disse que ele teria o nível INFO, mas agora preciso dizer em que classe este logger será utilizado. Vamos usar a classe que tem o main.
public static void main(String[] args) {
Logger logger = Logger.getLogger(“lopes”);
logger.info(“iniciando aplicação”);
logger.debug(“debug here”);
Usuario usuario = new Usuario();
usuario.setNome(“camilo”);
usuario.setEmail(“log4j”);
UsuarioDao usuarioDao = new UsuarioDao();
usuarioDao.save(usuario);
logger.info(“usuario salvo no banco com sucesso”);
Observe o nome que passei para o método getLogger(), o mesmo que definimos no arquivo properties, assim ele vai saber o nível a ser configurado, nesse caso foi INFO, então nada de debug é gravado no arquivo.
Note: habilitei o Hibernate para imprimir a instrução SQL, via Log4j
#configurando o hibernate no log4j
log4j.category.org.hibernate.SQL=DEBUG
Detalhes: http://docs.jboss.org/hibernate/core/3.6/reference/en-US/html/session-configuration.html#configuration-logging
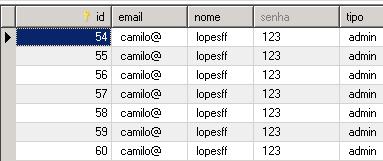
Na imagem abaixo temos o resultado do console:
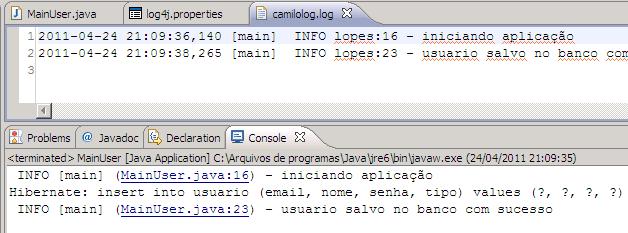
Aqui temos o console e o que foi gravado no arquivo de log (camilolog.log)
Vamos provocar uma exceção, e deixar o banco de dados (no meu caso MySQL) down. Para isso bastar dar um stop, em seu banco.

E dai conseguimos ver o erro de conexão no arquivo de LOG.
Claro que não vamos fazer isso para 100 classes que tivemos em um projeto, apenas para aquelas que precisam receber um tratamento diferenciado, que é preciso ir para o LOG, as demais ficam com o nível default definido no rootCategory.
Nomeação do logger
Não sei perceberam, mas há uma desvantagem em criarmos qualquer nome para o logger, como “lopes”, pois o resultado é:
2011-04-24 21:45:17,578 [main] INFO lopes:16 – iniciando aplicação
quem é lopes? O melhor é colocar o path da classe, assim:
log4j.category.br.com.camilolopes.dao=INFO
E precisamos mudar nossa variavel logger, passando apenas a classe:
Logger logger = Logger.getLogger(DAO.class);
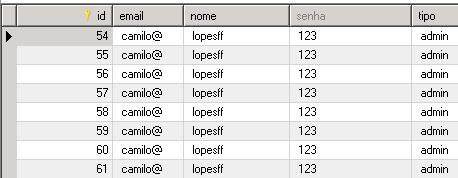
Ao executar temos o seguinte resultado:
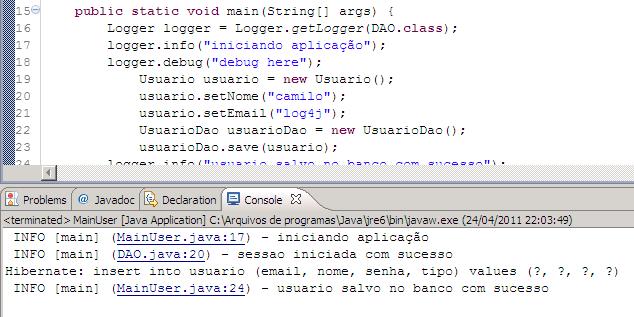
Observe que agora salvamos de onde vem INFO, pois temos a classe e a linha, para isso alteramos o ConvertionPattern, que grava no arquivo:
log4j.appender.fileOut.layout.ConversionPattern=%d [%t] %5p %F:%L – %m%n
Trocamos o %c por %F. Dar uma olhada na documentação tem muita coisa bacana:
http://logging.apache.org/log4j/1.2/apidocs/org/apache/log4j/PatternLayout.html
O resultado:

Não esqueça de dar um refresh, em seu projeto, para que o arquivo de LOG apareça, um atalho é selecionar o projeto e apertar F5.
Vou ficando por aqui e espero que tenham gostado do post.
abraços, see ya!!
 Olá Pessoal,
Olá Pessoal,