Opa! Pessoal,
O post de hoje vou apresentar como criar o relacionamento oneToMany / ManyToOne de forma simples. Quem ai nunca passou por algum tipo de problema ao criar esse tipo de relacionamento? Algo como de não criar a FK e só persistir uma das tabelas etc. Estarei apenas focando em como definir os relacionamentos à nível de código e para isso teremos code apenas para o objetivo do post. Quero evitar posts grandes sem necessidade.
lets go…
Required
– Vou assumir que se você está lendo este post é pq já está brincando com o Hibernate e agora precisa fazer um relacionamento entre as suas tabelas, então parte de configuração do framework, ou explicação dos métodos serão omitidos, qualquer dúvida consulte outros posts no blog na categoria Hibernate, e veja como ter o ambiente funcionando.
– A classe DAO nos códigos é que possui o trabalho de persistência, ela não é requirida para o post, pois vc uma vez que podemos obter o begin(), save(), commit() etc do hibernate por diversas formas.
– Hibernate 3.x
– MySql 5
OneToMany
O relacionamento OneToMany é bem usado, e são poucas vezes que de fato não precisamos te-lo, então é aquele lance se não precisou até hoje, espere mais um pouco que essa necessidade vai nascer. Vamos tirar a vantagem dos annotations e veremos @OneToMany e @ManyToOne ao invés dos .hbm, Como exemplo há vários cenários para exemplificar este tipo de relacionamento, tais como: um time de futebol tem vários jogadores, uma infra-estrutura tem vários servidores, porém um jogador só pode jogar em um time(ou não depende da regra de negócio, aqui está o pulo do gato), e um servidor está em uma infra-estrutura.
Note: Há casos que um jogador joga mais de um time, daí temos o ManyToMany.
Para criar esse tipo de relacionamento temos que identificar o ponto chave do relacionamento entre as classes, como por exemplo, para um Time de futebol, temos que saber que há uma lista com os jogadores que pertencem ao clube, uma vez que um team não tem apenas 1 jogador este pode ter de 0..X(mesmo sem jogadores ele pode ser considerado um team de futebol, mas está sem grana e demitiu todos os jogadores). Eu costumo chamar de HAS-AN List something (tem uma lista de alguma coisa).
A seguir temos a class bean que representa o Team (por boas práticas elas não deveria extends DAO, porém fiz aqui para ser mais pratico e fazer sentindo com as invocações do Hibernate que temos no code).
@Entity
public class Team extends DAO{
@Id
@GeneratedValue
private long id;
@Column
private String nameTeam;
private List<Player> players;
Usando @OneToMany
Agora vamos usar o relacionamento apropriado para a classe,a seguir temos o code atualizado:
@Entity
public class Team {
private String nameTeam;
@OneToMany(mappedBy = “team”, targetEntity = Player.class, fetch = FetchType.LAZY, cascade = CascadeType.ALL)
private List<Player> players;
mappedBy = informamos o nome da variavel de instância que vai indicar a quem aquele One pertence, ou seja, um jogador ele deve dizer a qual time este está associado.
TargetEntity = informa qual a entidade estamos associando
FetchType.Lazy = foi escolhido por performace
cascade = ALL para permitir alterações em todos os relacionamentos.
Pronto, já dizemos que um TEAM tem muitos jogadores (uma lista )
Usando @ManyToOne
Na classe que representa o MANY(do manyToOne), que nesse caso é a Player, teremos uma anotação @ManyToOne na variavel de instancia que representa o TEAM.
@Entity
public class Player {
@Id
@GeneratedValue
private long id;
private String nickName;
@ManyToOne
@JoinColumn(name=“team_id”)
private Team team;
@JoinColumn = informamos o nome que terá o FK.
Ao rodar o código main na class Team:
public static void main(String args[]) {
Team team1 = new Team();
team1.setNameTeam(“São Paulo”);
Player jogador1 = new Player();
Player jogador2 = new Player();
jogador1.setNickName(“Rogerio Ceni”);
jogador2.setNickName(“Luiz Fabiano”);
// has-an associando o jogador ao team
jogador1.setTeam(team1);
jogador2.setTeam(team1);
begin();
getSession().save(team1);
getSession().save(player1);
getSession().save(player2);
commit();
}
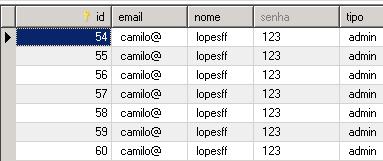
Talvez você tenha pensado que apenas 1 (um) save() seria necessario, mas não é, pois precisamos colocar a instancia dos players com a session, para que este se torne um objeto persistente do contrario, o Hibernate não o poder de persistir no banco. O resultado:


O team do São Paulo tem dois jogadores, observe que o ID do team aparece na table do Player(team_id) assim sabemos a qual time este pertence.
Erros comuns durante a programação:
-
esquecer de associar as instâncias envolvidas no relacionamento, se eu esquecer de dizer a qual team um jogador pertence, não teremos o resultado esperado e o resultado na sua tabela será NULL, caso seja permitido esse valor na coluna.
-
Não salvar as instâncias que serão persistidas é outro fato comum, quem está fazendo pela primeira acredita que dar um save apenas na classe que representar One (team), é o sufuciente e por alguma mágina o Hibernate vai saber quais outras instancias devem ser persistidas, ai vem a pergunta, como o Hibernate vai saber, se você não transformou o “objeto java” criando em um objeto-persistent?
Espero que tenham gostado do post, vou ficando por aqui.
Abracos see you next post!!! 🙂